
Paper Reading: Progressive Neural Networks
Published:
Progressive Neural Networks
Citation Count: 3443 Organization: DeepMind Year: 2016
Background
The paper Progressive Neural Networks is one of the earliest and most influential works in the field of continual learning. Although its core idea is simpler compared to other foundational papers—such as Overcoming Catastrophic Forgetting in Neural Networks (EWC)—it represents a different category of approaches. Instead of using regularization to prevent forgetting, it tackles the problem by expanding the network and adding new parameters when learning new tasks. Let’s take a closer look at how it works!
Method
If you’re familiar with regularization-based methods, you’ll recall that their key idea is to constrain the model—typically through some form of penalty—so it doesn’t forget previously learned tasks when adapting to new ones. A hidden assumption in that approach is the desire to keep model complexity fixed.
But what if model size isn’t a hard constraint? If we allow the network to grow, we can simply add new capacity for new tasks and preserve the existing knowledge as-is. This is the central idea behind Progressive Neural Networks.
Each column in the below architecture represents a sub-network dedicated to a specific task. Initially, only the first column exists to handle the first task. Whenever a new task exists, a new column is added to learn that task.
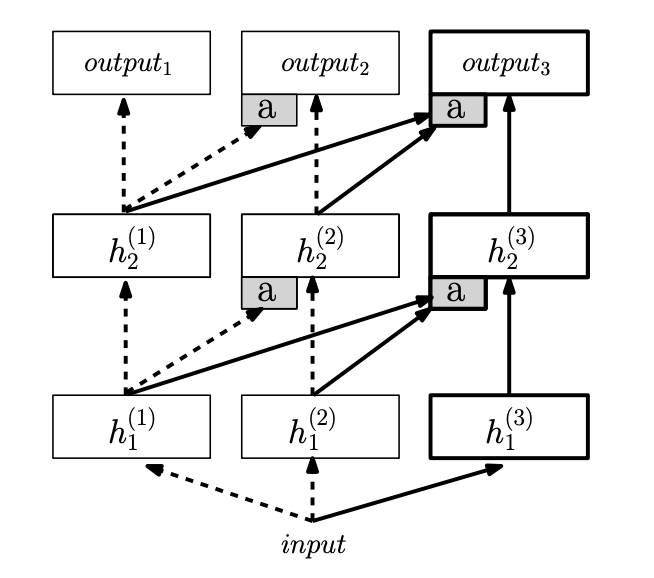
Here are a few key points worth noting:
- Knowledge reuse: Unlike training a completely separate model for each new task, Progressive Neural Networks allow for knowledge transfer via lateral connections. These connections link each layer in the new column to the previous layers in trained columns, enabling the model to reuse useful representations.
- No forgetting: When learning new tasks, the parameters of previously trained columns are frozen. This is the fundamental reason why catastrophic forgetting does not occur.
Conclusion
Progressive Neural Networks is a relatively easy-to-understand paper with clear intuition and straightforward implementation. Still, it’s important to appreciate why it belongs in the continual learning family and how its design philosophy differs from regularization-based approaches. While it trades off parameter efficiency for simplicity and robustness to forgetting, it remains a foundational method in the field—and an important one to understand.
Leave a Comment