
Paper Reading: Learning without Forgetting
Published:
Learning without Forgetting
Citation Count: 5576
Main Idea: Use old model’s prediction on new data to regularize the network from forgetting old tasks when learning new tasks (under the limitation that has no access to previous data)
Organization: UIUC
Year: 2016
Paper Link
https://arxiv.org/pdf/1606.09282
Background
There are three common approaches to learning new classification tasks while maintaining performance on previously learned ones, each with distinct advantages and disadvantages:
- Feature extraction: The original network’s feature extraction and classifier components remain fixed, while a new classifier is added to the feature extractor’s output to learn new tasks.
- Best performance on original tasks
- Suboptimal performance on new tasks since features are optimized for old tasks
- Fine Tuning: Both the original network’s feature extractor and the new classifier are tuned for the new task.
- Good performance on new tasks
- Degraded performance on old tasks as features become optimized for new tasks
- Joint Training: Data from both old and new tasks are combined for training, with the feature extractor and all classifiers being tuned simultaneously.
- Good performance on both old and new tasks
- Requires access to old task data
- Longer training time due to increased data volume and full network retraining
To combine the advantages and eliminate the disadvantages of these methods, the authors proposed Learning without Forgetting (LWF), which offers:
- Good performance on both new and old tasks
- No need for old task data
- Training time comparable to fine-tuning when learning new tasks
Main Idea
While the original paper contains many details, the core concept is straightforward:
Joint training achieves good performance on both old and new tasks but requires old data. To overcome this limitation, we can use an alternative approach: have the original network classify new data for old tasks, recording these outputs as a representation of the original network. Then, while learning new tasks, train the network to maintain these recorded outputs (feature extractor + old classifier) while simultaneously learning the new tasks (feature extractor + new classifier).
The core idea can be expressed mathematically as follows:
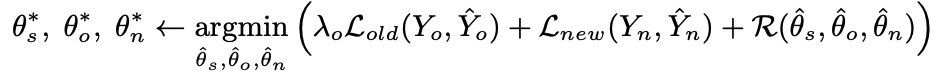
where $s$ represents the feature extractor, $o$ relates to the old classifier, $s$ relates to the new classifier, and $R$ represents regularization terms.
Experimental Results
The experimental results demonstrate that LWF achieves a good balance between old and new tasks, as illustrated below:
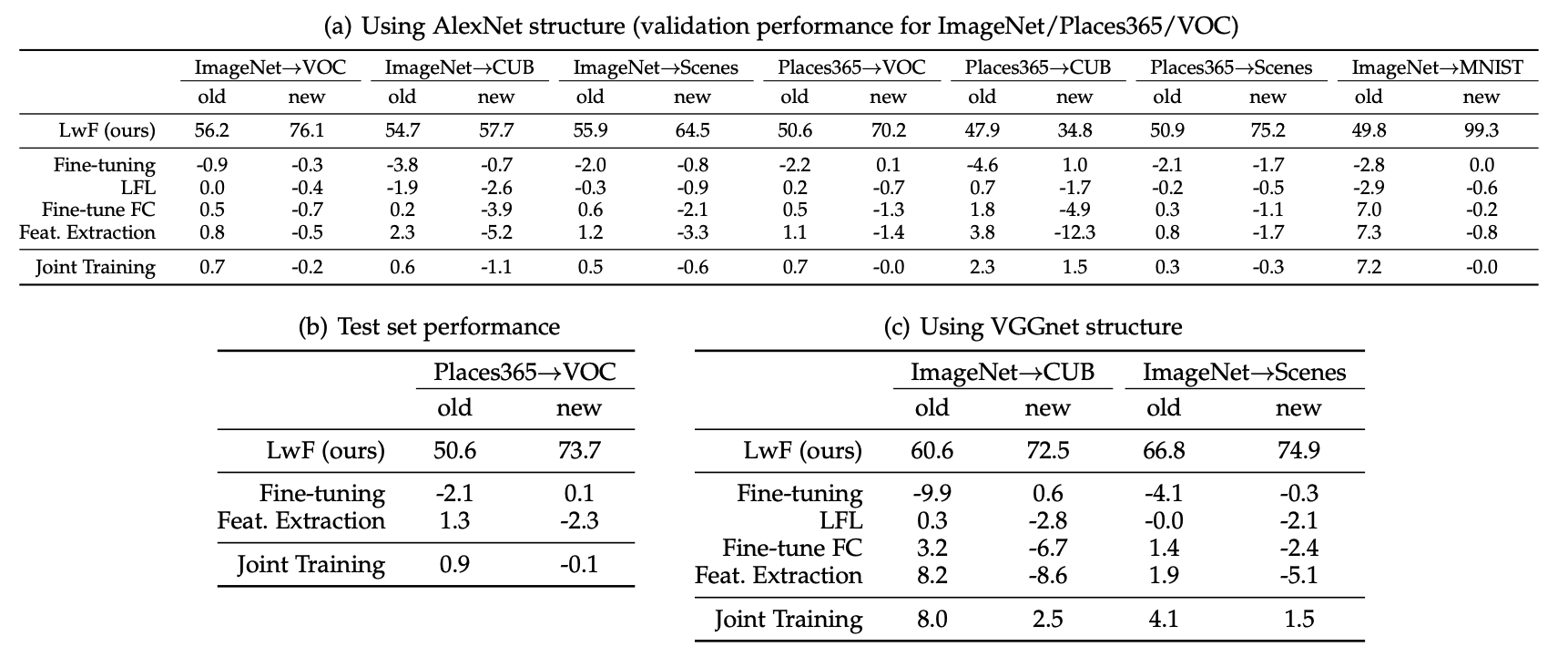
While most ablation studies yield minor insights, one notable finding is that task dissimilarity affects performance: when new tasks differ significantly from old ones, performance on old tasks deteriorates across almost all methods. This phenomenon is also mentioned by other papers.
Conclusion
Learning without Forgetting stands as a seminal paper in continual learning. Though its method and performance may seem modest by today’s standards, it remains widely cited in subsequent research. Understanding this work provides crucial insights into basic approaches for preventing catastrophic forgetting. When studied alongside other key papers in continual learning, it helps illuminate the field’s evolution and underlying principles.
Leave a Comment